
Enhance monitoring and debugging for AWS Glue jobs using new job observability metrics: Part 2
AWS Big Data
FEBRUARY 13, 2024
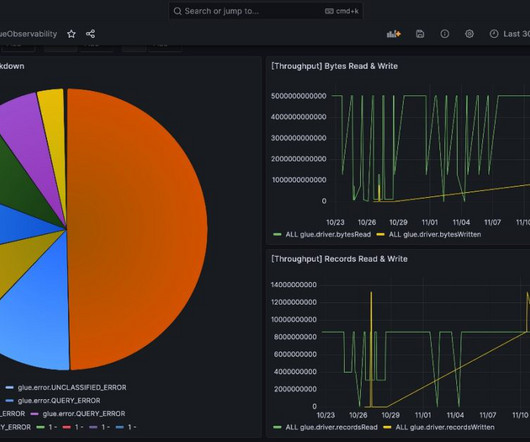
AWS Glue has made this more straightforward with the launch of AWS Glue job observability metrics , which provide valuable insights into your data integration pipelines built on AWS Glue. This post, walks through how to integrate AWS Glue job observability metrics with Grafana using Amazon Managed Grafana.



























Let's personalize your content