
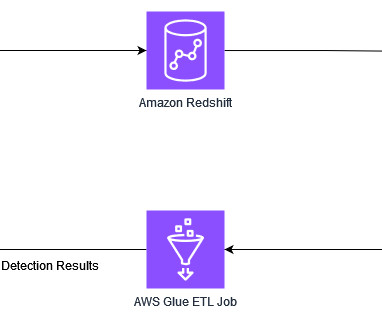
Automatically detect Personally Identifiable Information in Amazon Redshift using AWS Glue
AWS Big Data
DECEMBER 15, 2023
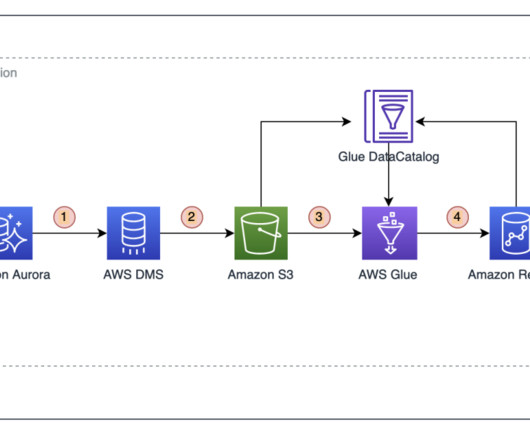
Many companies identify and label PII through manual, time-consuming, and error-prone reviews of their databases, data warehouses and data lakes, thereby rendering their sensitive data unprotected and vulnerable to regulatory penalties and breach incidents. For our solution, we use Amazon Redshift to store the data.





















Let's personalize your content