

Modernizing the Data Warehouse: Challenges and Benefits
BI-Survey
AUGUST 21, 2020
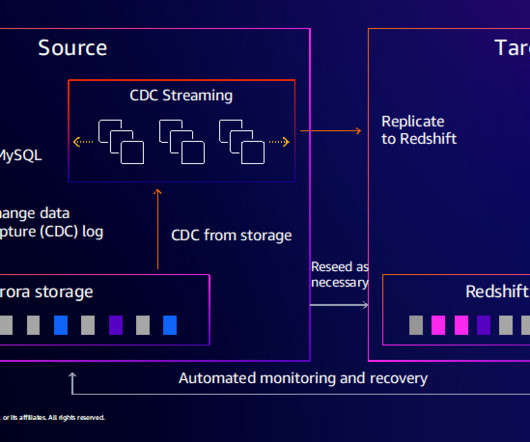
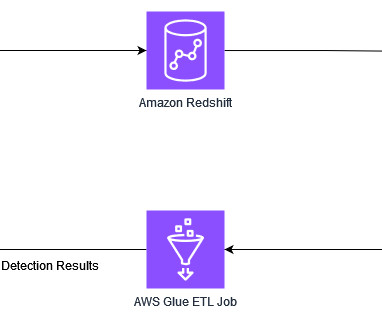
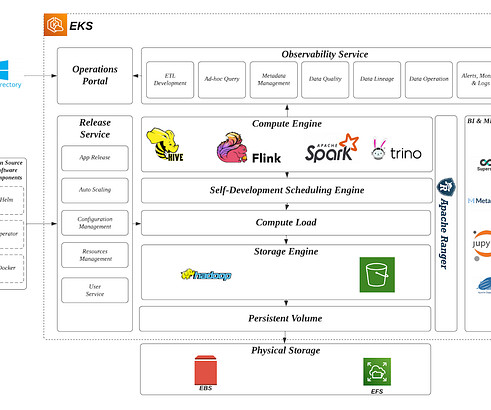
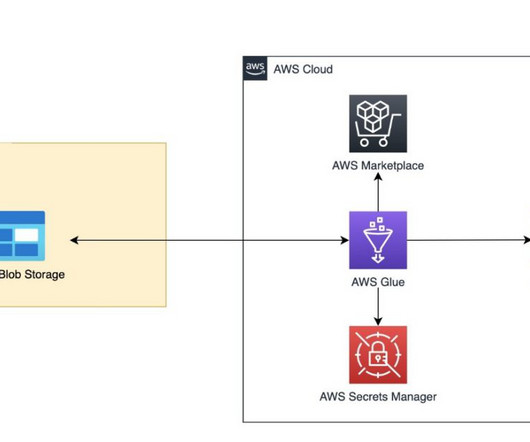
But what are the right measures to make the data warehouse and BI fit for the future? Can the basic nature of the data be proactively improved? The following insights came from a global BARC survey into the current status of data warehouse modernization. They are opting for cloud data services more frequently.














































Let's personalize your content