
Governing data in relational databases using Amazon DataZone
AWS Big Data
MAY 7, 2024
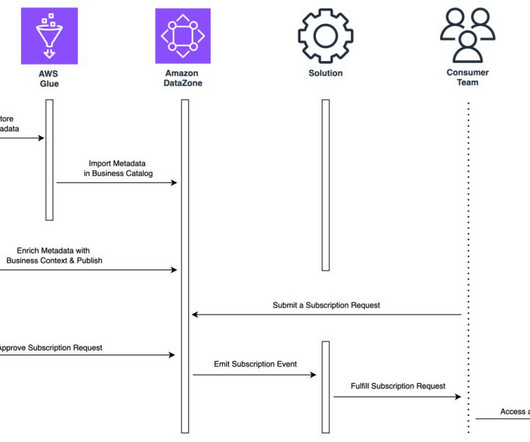
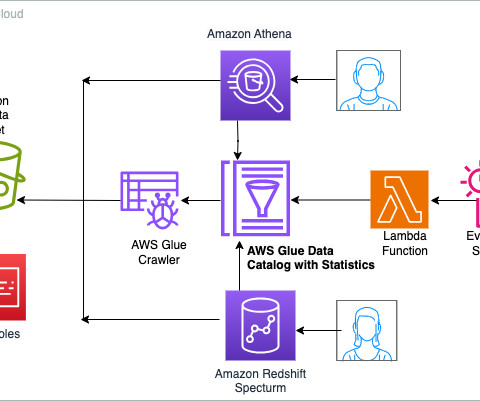
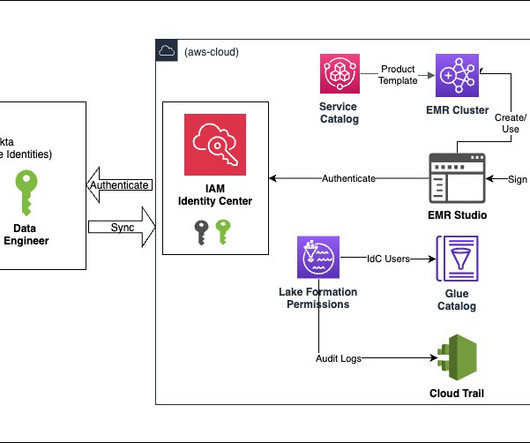
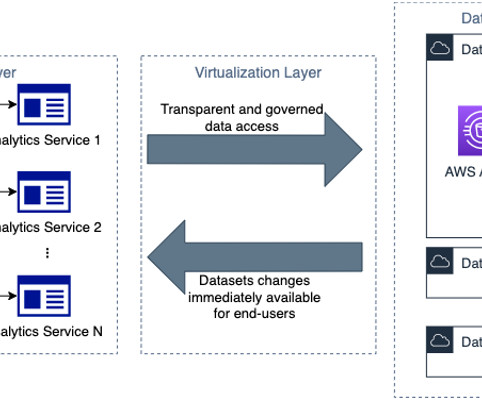
Data governance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or data lakes cataloged with the AWS Glue data catalog.



























Let's personalize your content