
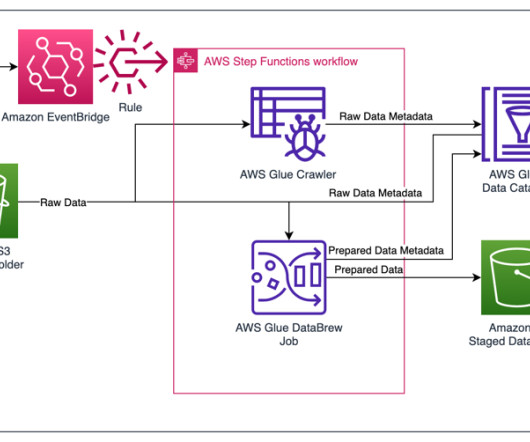
Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
AWS Big Data
AUGUST 1, 2023
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Managing projects with Jira leads to rich datasets, which can provide historical and predictive insights about project and development efforts. An AWS account and a login with access to the AWS Management Console.












































Let's personalize your content