
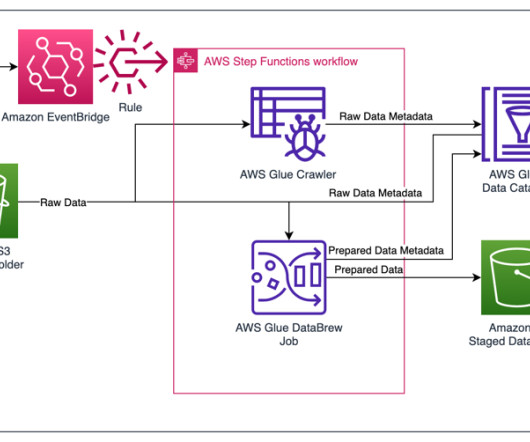
Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
AWS Big Data
AUGUST 1, 2023
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Companies often take a data lake approach to their analytics, bringing data from many different systems into one place to simplify how the analytics are done. Search for the Jira Cloud connector.



























Let's personalize your content