
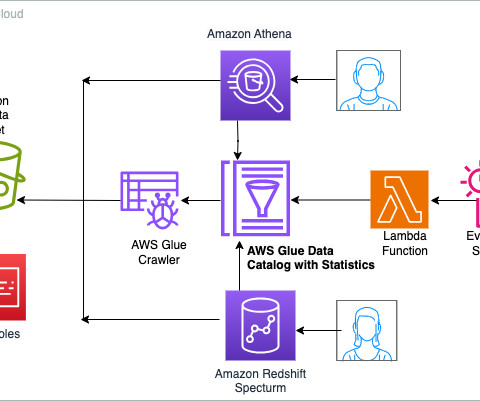
Enhance query performance using AWS Glue Data Catalog column-level statistics
AWS Big Data
NOVEMBER 22, 2023
Today, we’re making available a new capability of AWS Glue Data Catalog that allows generating column-level statistics for AWS Glue tables. These statistics are now integrated with the cost-based optimizers (CBO) of Amazon Athena and Amazon Redshift Spectrum , resulting in improved query performance and potential cost savings.























Let's personalize your content