

Orchestrate an end-to-end ETL pipeline using Amazon S3, AWS Glue, and Amazon Redshift Serverless with Amazon MWAA
AWS Big Data
APRIL 25, 2024
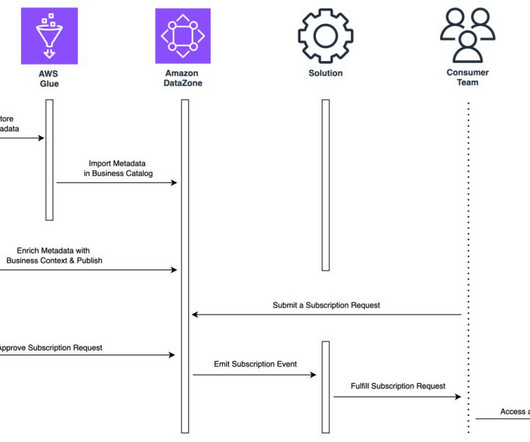
As the queries finish running, an UNLOAD operation is invoked from the Redshift data warehouse to the S3 bucket in Account A. Cross-account access has been set up between S3 buckets in Account A with resources in Account B to be able to load and unload data. For more information, see Accessing an Amazon MWAA environment.
























Let's personalize your content