

Optimize write throughput for Amazon Kinesis Data Streams
AWS Big Data
JUNE 3, 2024
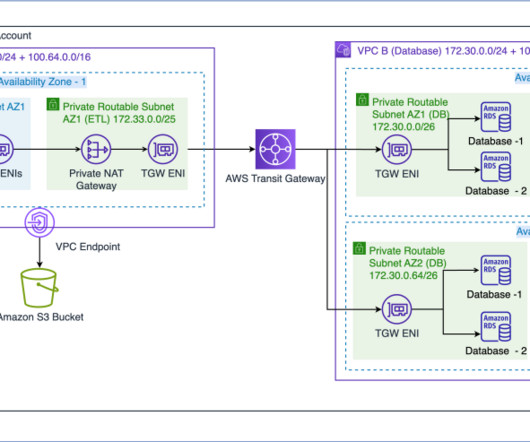
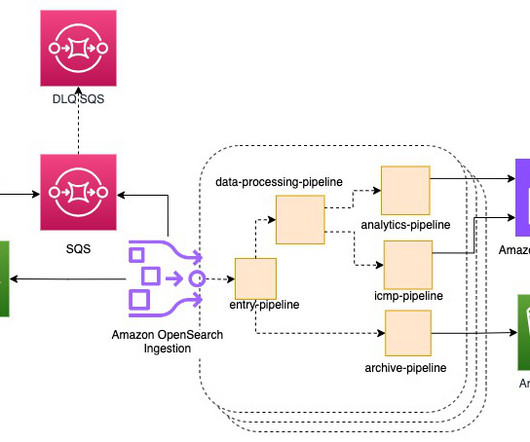
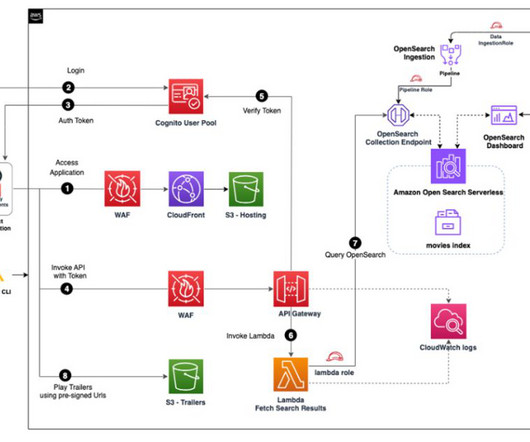
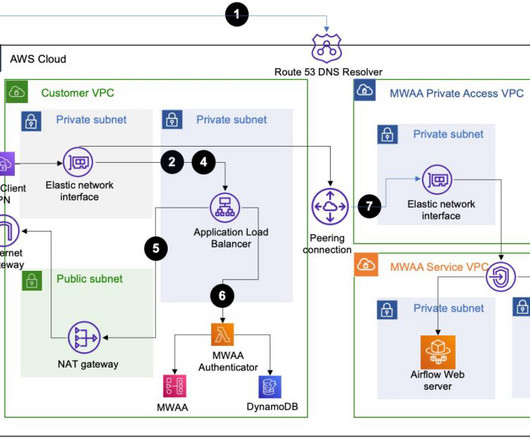
If all of them are fully utilized during a minute window specified using -from and -to arguments, the host running KHS will receive at least 1 MB * 100 * 60 = 6000 MB = approximately 6 GB data. The first issue with this is, if the host crashes before the records could be written, you’ll experience data loss.



































Let's personalize your content