
Business Strategies for Deploying Disruptive Tech: Generative AI and ChatGPT
Rocket-Powered Data Science
FEBRUARY 15, 2023
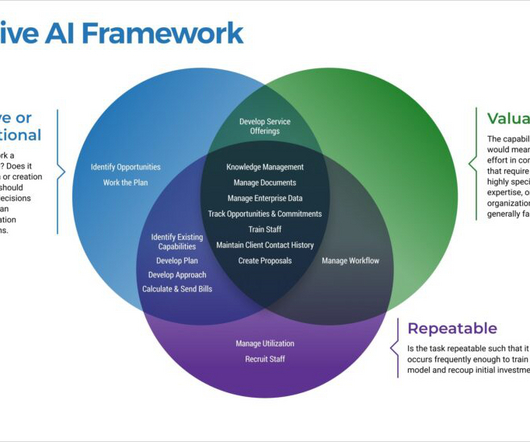
3) How do we get started, when, who will be involved, and what are the targeted benefits, results, outcomes, and consequences (including risks)? Those F’s are: Fragility, Friction, and FUD (Fear, Uncertainty, Doubt). These changes may include requirements drift, data drift, model drift, or concept drift. Test early and often.
















Let's personalize your content