

Optimize data layout by bucketing with Amazon Athena and AWS Glue to accelerate downstream queries
AWS Big Data
APRIL 25, 2024
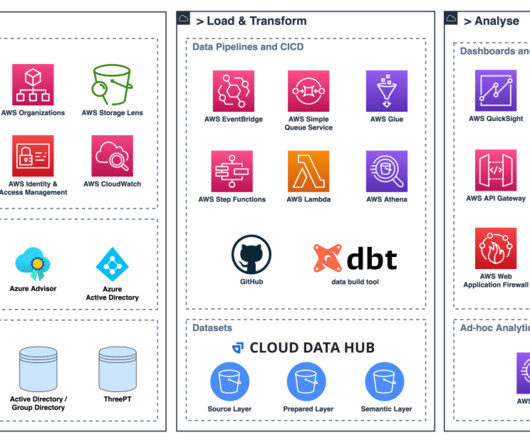
Data lakes provide a centralized repository for data from various sources, enabling organizations to unlock valuable insights and drive data-driven decision-making. However, as data volumes continue to grow, optimizing data layout and organization becomes crucial for efficient querying and analysis.




















Let's personalize your content