
Apache Iceberg optimization: Solving the small files problem in Amazon EMR
AWS Big Data
OCTOBER 3, 2023
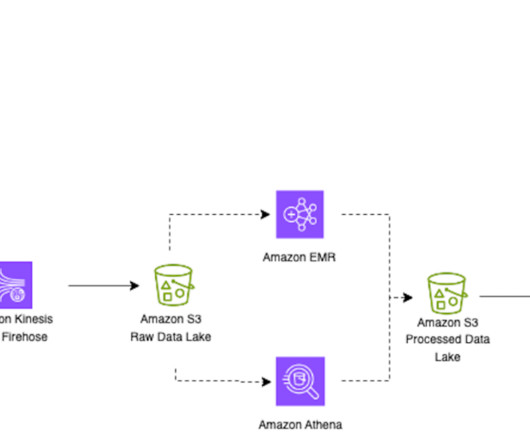
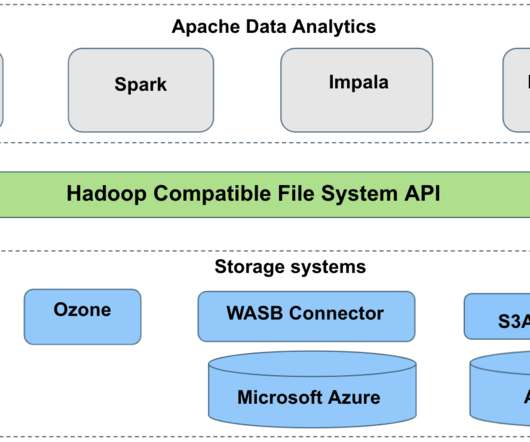
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations. with Spark 3.3.2,













































Let's personalize your content