

How Eightfold AI implemented metadata security in a multi-tenant data analytics environment with Amazon Redshift
AWS Big Data
NOVEMBER 29, 2023
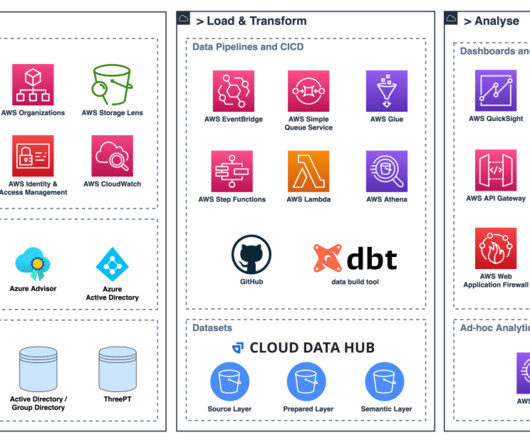
As part of the Talent Intelligence Platform Eightfold also exposes a data hub where each customer can access their Amazon Redshift-based data warehouse and perform ad hoc queries as well as schedule queries for reporting and data export. Many customers have implemented Amazon Redshift to support multi-tenant applications.





































Let's personalize your content