
Uncertainties: Statistical, Representational, Interventional
The Unofficial Google Data Science Blog
DECEMBER 14, 2021
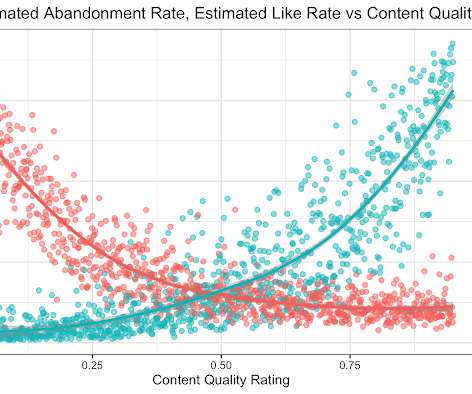
by AMIR NAJMI & MUKUND SUNDARARAJAN Data science is about decision making under uncertainty. Some of that uncertainty is the result of statistical inference, i.e., using a finite sample of observations for estimation. But there are other kinds of uncertainty, at least as important, that are not statistical in nature.



















Let's personalize your content