

Your Generative AI LLM Needs a Data Journey: A Comprehensive Guide for Data Engineers
DataKitchen
FEBRUARY 27, 2024
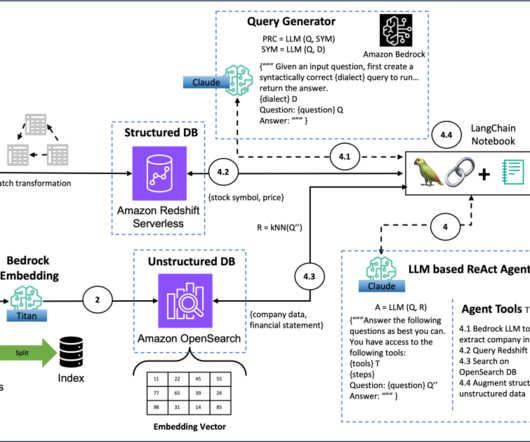
Your LLM Needs a Data Journey: A Comprehensive Guide for Data Engineers The rise of Large Language Models (LLMs) such as GPT-4 marks a transformative era in artificial intelligence, heralding new possibilities and challenges in equal measure.













Let's personalize your content