

Extend geospatial queries in Amazon Athena with UDFs and AWS Lambda
AWS Big Data
MARCH 17, 2023
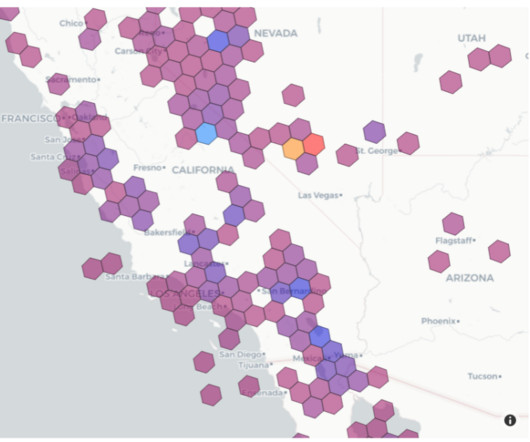
Amazon Athena is a serverless and interactive query service that allows you to easily analyze data in Amazon Simple Storage Service (Amazon S3) and 25-plus data sources, including on-premises data sources or other cloud systems using SQL or Python. H3 divides the globe into equal-sized regular hexagons.



















Let's personalize your content