


The Five Use Cases in Data Observability: Mastering Data Production
DataKitchen
MAY 10, 2024
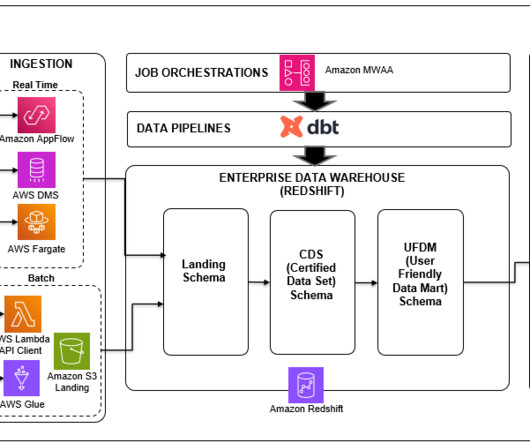
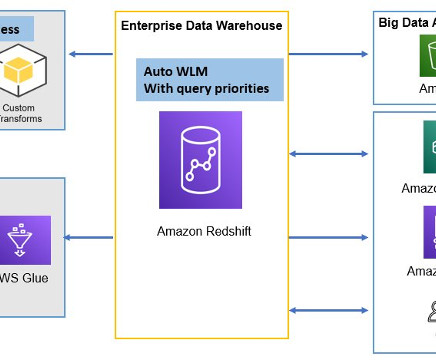
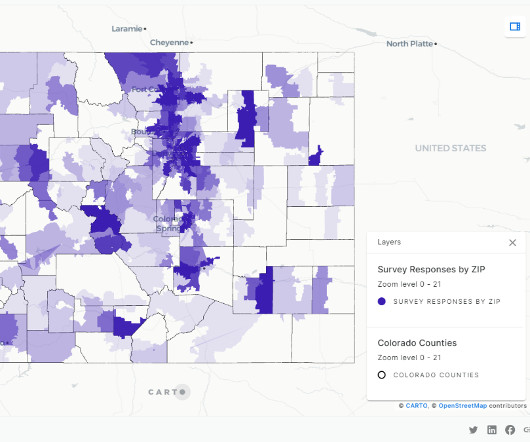
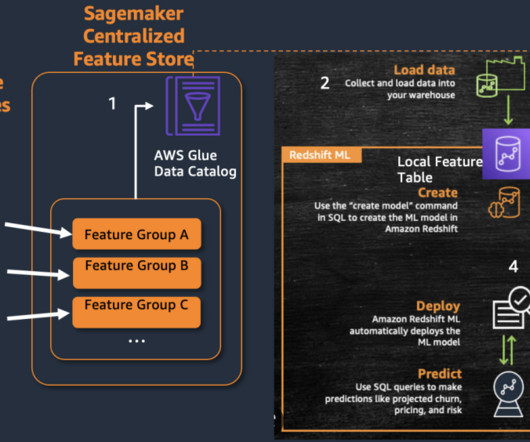
The Five Use Cases in Data Observability: Mastering Data Production (#3) Introduction Managing the production phase of data analytics is a daunting challenge. Overseeing multi-tool, multi-dataset, and multi-hop data processes ensures high-quality outputs.









































Let's personalize your content