


Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 data lakes
AWS Big Data
MAY 24, 2023
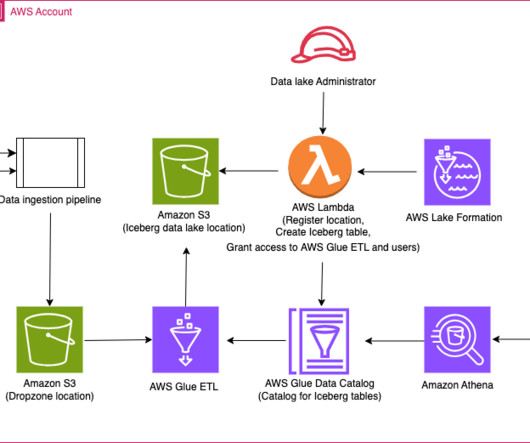
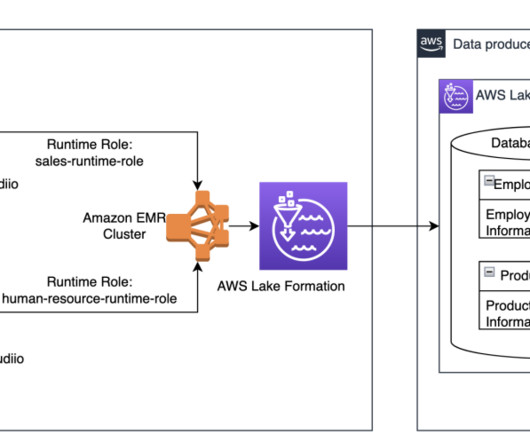
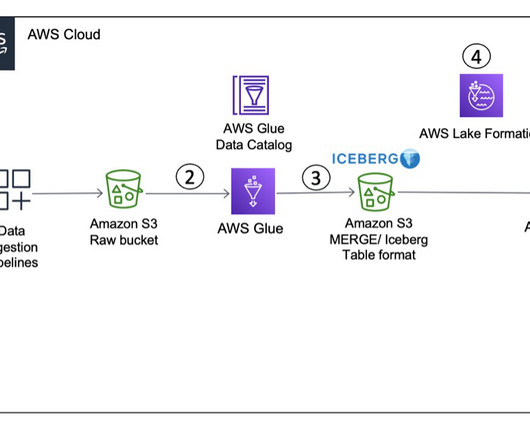
You can use Amazon S3 Lifecycle configurations and Amazon S3 object tagging with Apache Iceberg tables to optimize the cost of your overall data lake storage. Amazon S3 uses object tagging to categorize storage where each tag is a key-value pair. and Spark 3.3.1. Amazon S3 deletes expired objects on your behalf.











































Let's personalize your content