


Advanced patterns with AWS SDK for pandas on AWS Glue for Ray
AWS Big Data
JUNE 5, 2023
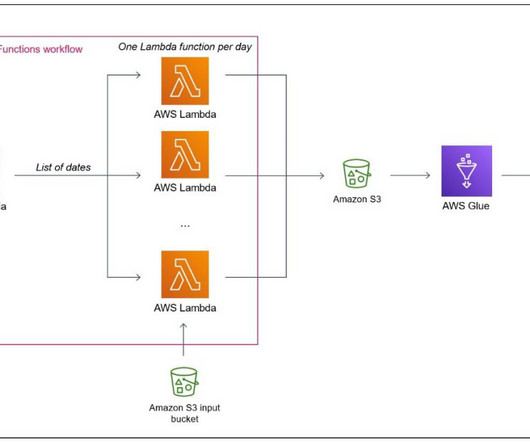
To illustrate these capabilities, we explored examples of writing Parquet files to Amazon S3 at scale and querying data in parallel with Athena. In this post, we show how to use some of these APIs in an AWS Glue for Ray job, namely querying with S3 Select, writing to and reading from a DynamoDB table, and writing to a Timestream table.

















Let's personalize your content