
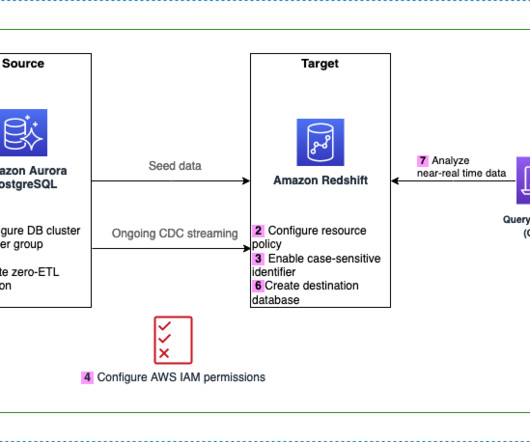
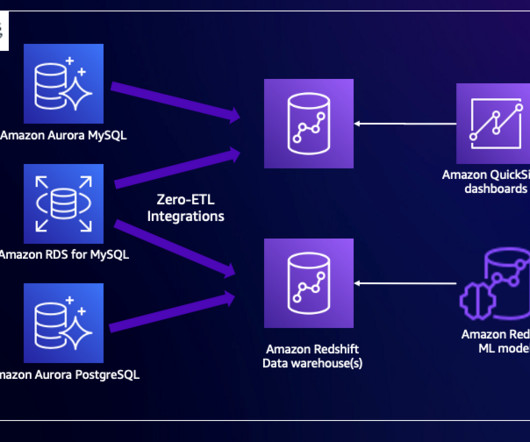
Achieve near real time operational analytics using Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift
AWS Big Data
APRIL 10, 2024
Create a role in the target account with the following permissions: { "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "redshift:DescribeClusters", "redshift-serverless:ListNamespaces" ], "Resource":[ "*" ] } ] } The role must have the following trust policy, which specifies the target account ID.
























Let's personalize your content