
A Guide To The Methods, Benefits & Problems of The Interpretation of Data
datapine
JANUARY 6, 2022
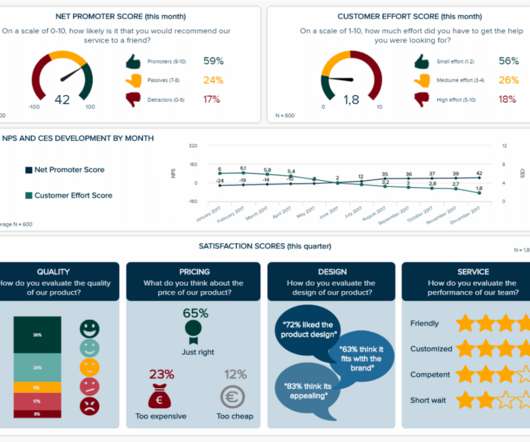
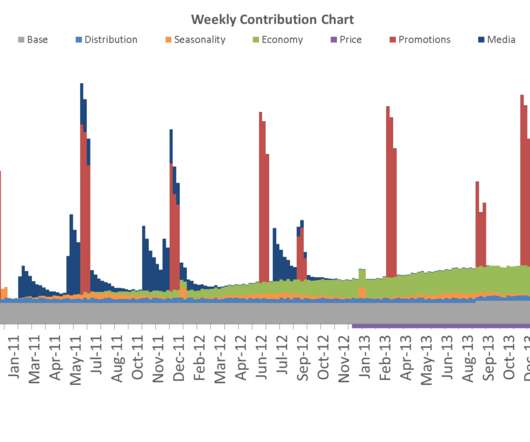
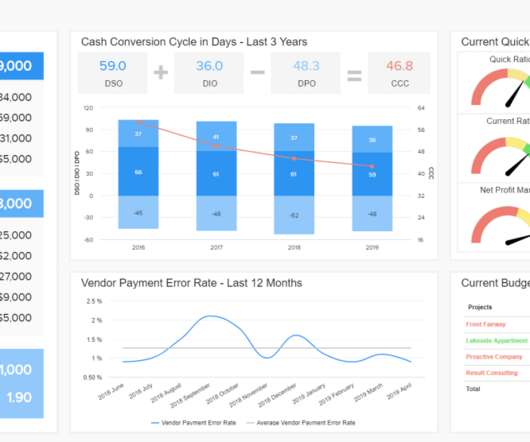
In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 More often than not, it involves the use of statistical modeling such as standard deviation, mean and median. Let’s quickly review the most common statistical terms: Mean: a mean represents a numerical average for a set of responses.




























Let's personalize your content