

Why you should care about debugging machine learning models
O'Reilly on Data
DECEMBER 12, 2019
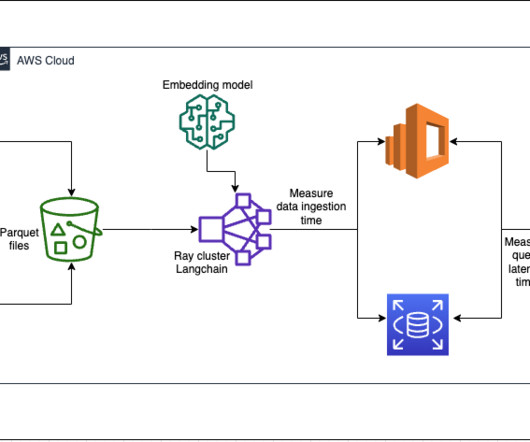
For all the excitement about machine learning (ML), there are serious impediments to its widespread adoption. There are several known attacks against machine learning models that can lead to altered, harmful model outcomes or to exposure of sensitive training data. [8] 2] The Security of Machine Learning. [3]





















Let's personalize your content