

How Cloudinary transformed their petabyte scale streaming data lake with Apache Iceberg and AWS Analytics
AWS Big Data
JUNE 10, 2024
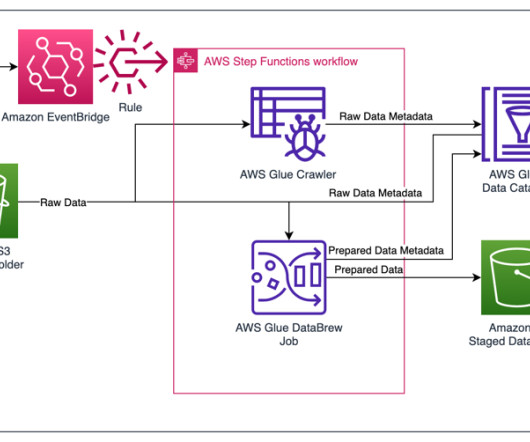
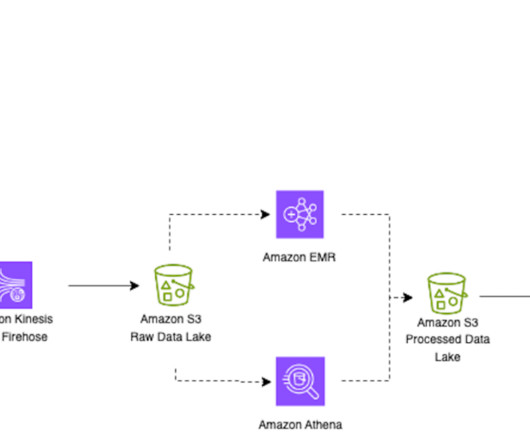
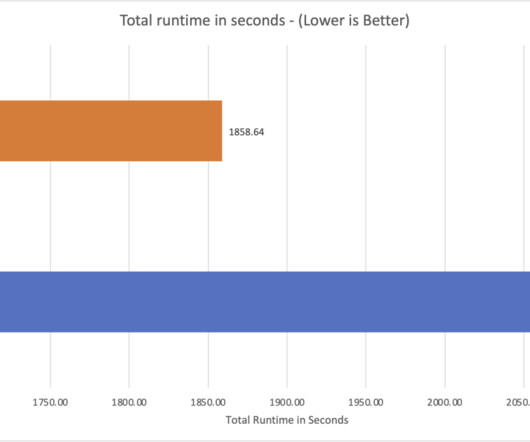
In this blog post, we dive into different data aspects and how Cloudinary breaks the two concerns of vendor locking and cost efficient data analytics by using Apache Iceberg, Amazon Simple Storage Service (Amazon S3 ), Amazon Athena , Amazon EMR , and AWS Glue.
















































Let's personalize your content