

Data Mesh 101: How Data Mesh Helps Organizations Be Data-Driven and Achieve Velocity
Ontotext
FEBRUARY 12, 2024
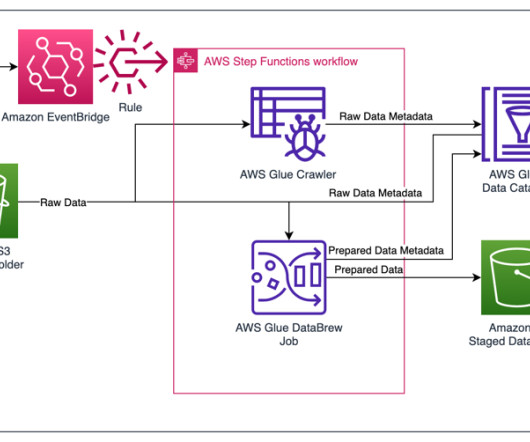
In the final part of this three-part series, we’ll explore ho w data mesh bolsters performance and helps organizations and data teams work more effectively. Usually, organizations will combine different domain topologies, depending on the trade-offs, and choose to focus on specific aspects of data mesh.























Let's personalize your content