

Cloudera Data Warehouse Demonstrates Best-in-Class Cloud-Native Price-Performance
Cloudera
JANUARY 15, 2021
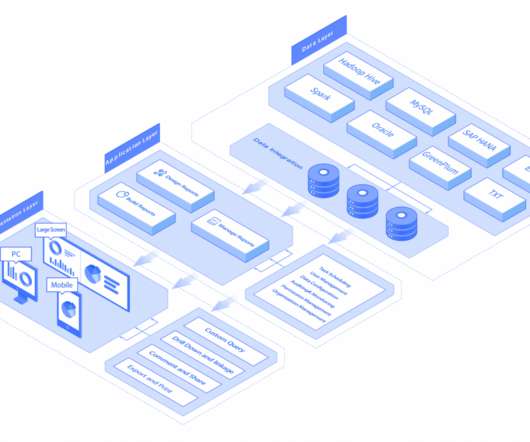
Cloud data warehouses allow users to run analytic workloads with greater agility, better isolation and scale, and lower administrative overhead than ever before. With pay-as-you-go pricing, platforms that deliver high-performance benefit users not only through faster results but also through direct cost savings.









































Let's personalize your content