

DS Smith sets a single-cloud agenda for sustainability
CIO Business Intelligence
DECEMBER 6, 2023
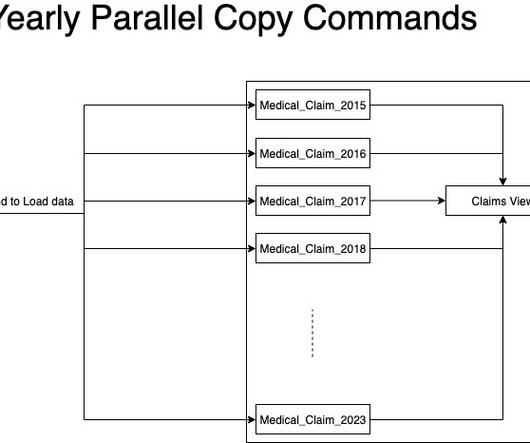
Its digital transformation began with an application modernization phase, in which Dickson and her IT teams determined which applications should be hosted in the public cloud and which should remain on a private cloud. Having that data in the cloud and piping it into our data pipelines is a much more effective way to do that.”



























Let's personalize your content