

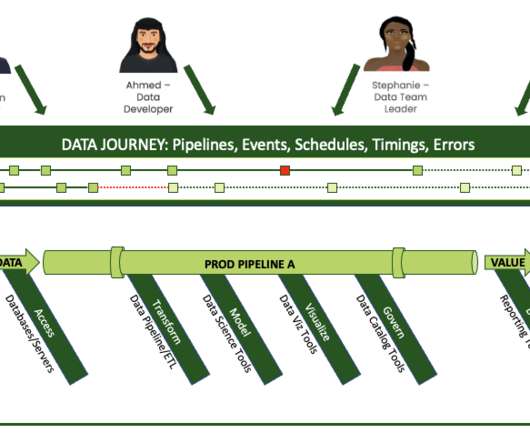
Navigating the Chaos of Unruly Data: Solutions for Data Teams
DataKitchen
NOVEMBER 10, 2023
Identifying Anomalies: Use advanced algorithms to detect anomalies in data patterns. Establish baseline metrics for normal database operations, enabling the system to flag deviations as potential issues. Building a Culture of Accountability: Encourage a culture where data integrity is everyone’s responsibility.




















Let's personalize your content