

Use Apache Iceberg in your data lake with Amazon S3, AWS Glue, and Snowflake
AWS Big Data
APRIL 3, 2024
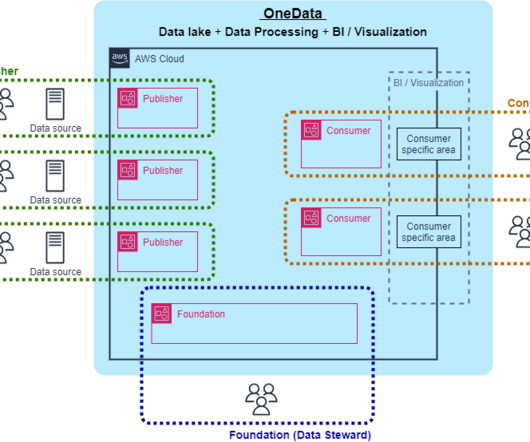
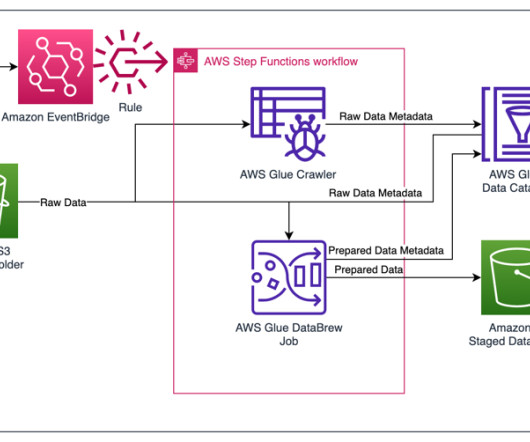
Businesses are constantly evolving, and data leaders are challenged every day to meet new requirements. Customers are using AWS and Snowflake to develop purpose-built data architectures that provide the performance required for modern analytics and artificial intelligence (AI) use cases.












































Let's personalize your content