
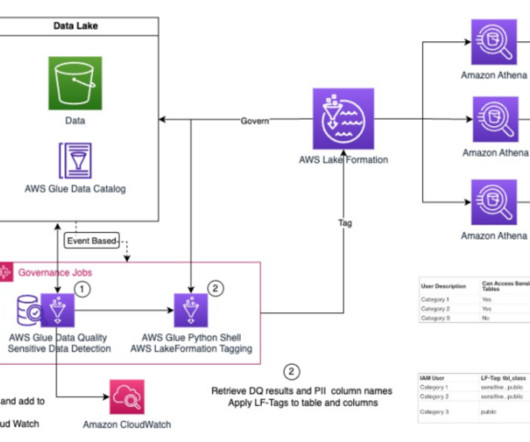
Automated data governance with AWS Glue Data Quality, sensitive data detection, and AWS Lake Formation
AWS Big Data
OCTOBER 10, 2023
Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake. Data confidentiality and data quality are the two essential themes for data governance.













































Let's personalize your content