

Build an Amazon Redshift data warehouse using an Amazon DynamoDB single-table design
AWS Big Data
JUNE 21, 2023
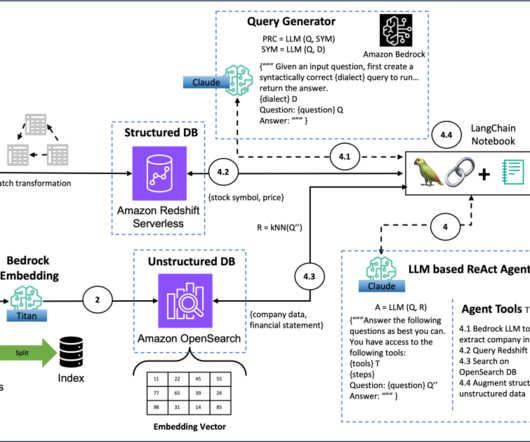
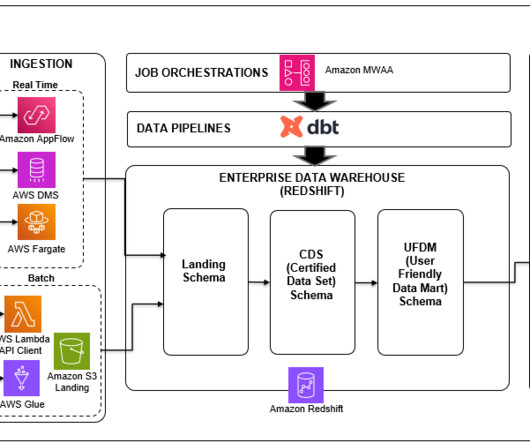
These types of queries are suited for a data warehouse. The goal of a data warehouse is to enable businesses to analyze their data fast; this is important because it means they are able to gain valuable insights in a timely manner. Amazon Redshift is fully managed, scalable, cloud data warehouse.


























Let's personalize your content