

Ten new visual transforms in AWS Glue Studio
AWS Big Data
MAY 9, 2023
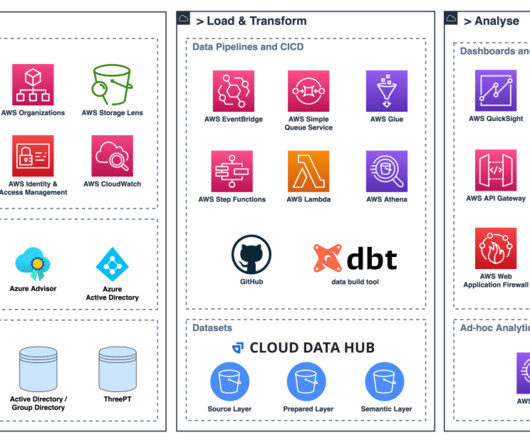
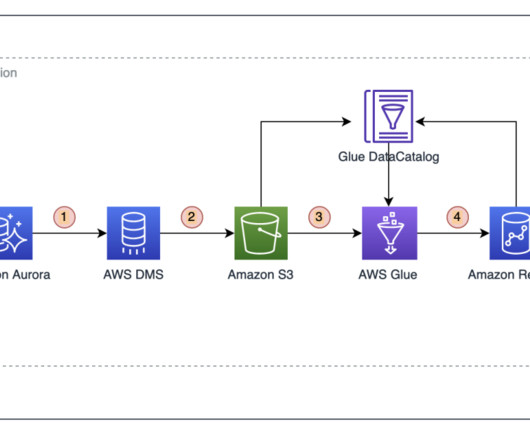
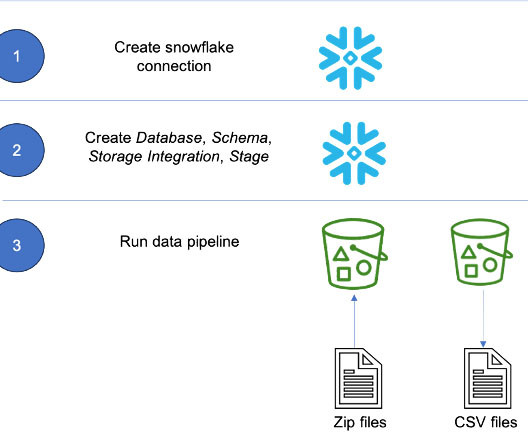
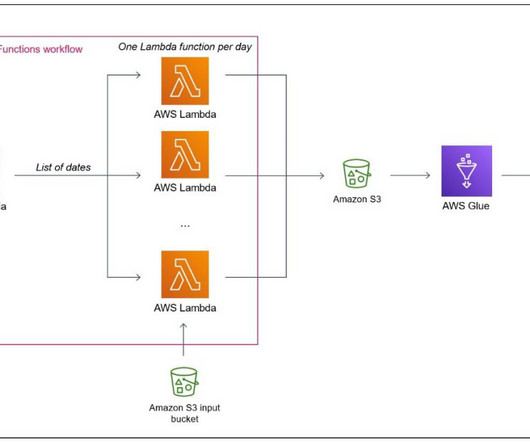
AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It allows you to visually compose data transformation workflows using nodes that represent different data handling steps, which later are converted automatically into code to run.



























Let's personalize your content