
Build a decentralized semantic search engine on heterogeneous data stores using autonomous agents
AWS Big Data
MAY 28, 2024
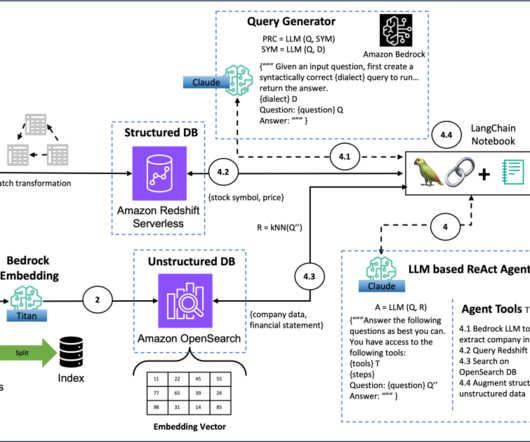
Run the notebook There are six major sections in the notebook: Prepare the unstructured data in OpenSearch Service – Download the SEC Edgar Annual Financial Filings dataset and convert the company financial filing document into vectors with Amazon Titan Text Embeddings model and store the vector in an Amazon OpenSearch Service vector database.



















Let's personalize your content