

How Eightfold AI implemented metadata security in a multi-tenant data analytics environment with Amazon Redshift
AWS Big Data
NOVEMBER 29, 2023
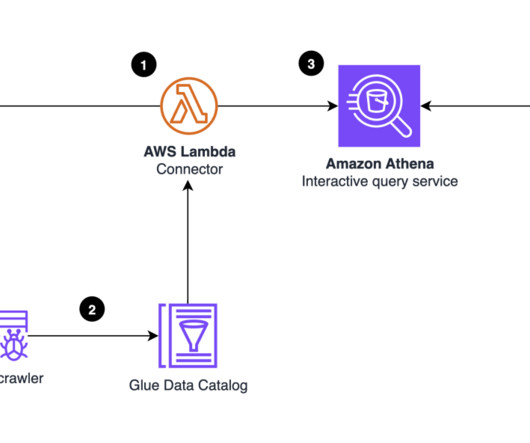
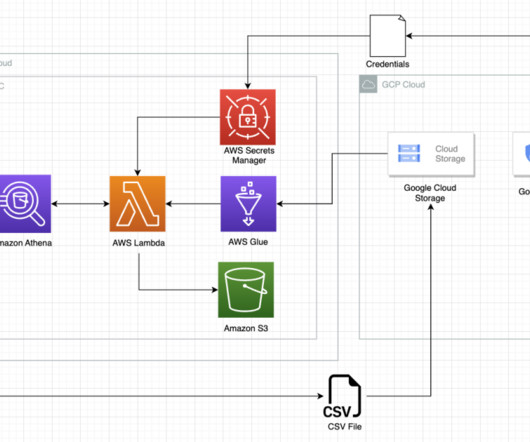
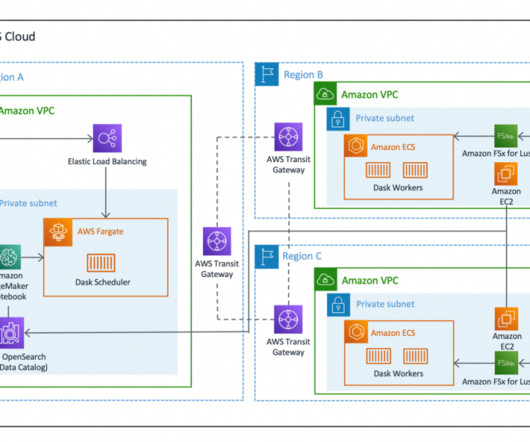
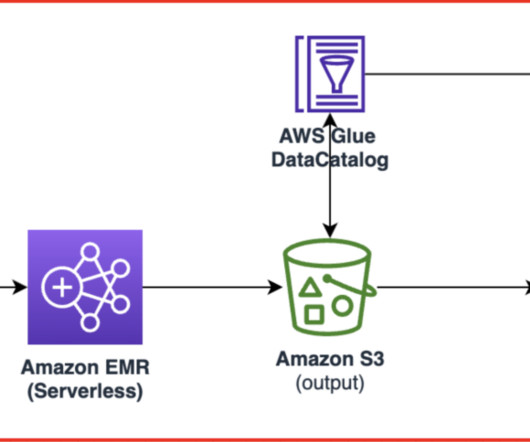
The Eightfold Talent Intelligence Platform integrates with Amazon Redshift metadata security to implement visibility of data catalog listing of names of databases, schemas, tables, views, stored procedures, and functions in Amazon Redshift. This post discusses restricting listing of data catalog metadata as per the granted permissions.









































Let's personalize your content