

The Ultimate Guide to Modern Data Quality Management (DQM) For An Effective Data Quality Control Driven by The Right Metrics
datapine
SEPTEMBER 29, 2022
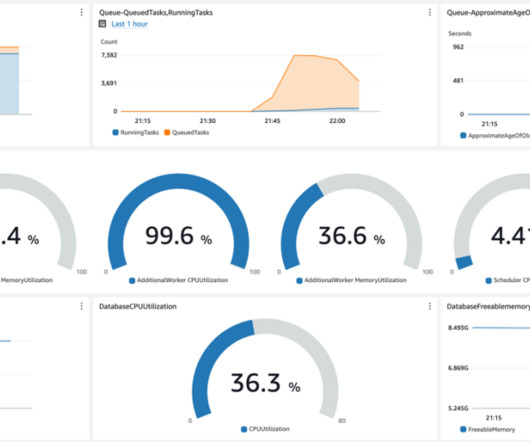
6) Data Quality Metrics Examples. Reporting being part of an effective DQM, we will also go through some data quality metrics examples you can use to assess your efforts in the matter. Data quality refers to the assessment of the information you have, relative to its purpose and its ability to serve that purpose.








































Let's personalize your content