
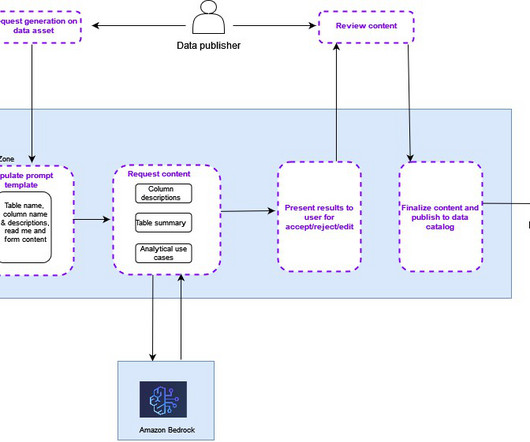
AI recommendations for descriptions in Amazon DataZone for enhanced business data cataloging and discovery is now generally available
AWS Big Data
APRIL 2, 2024
Without the right metadata and documentation, data consumers overlook valuable datasets relevant to their use case or spend more time going back and forth with data producers to understand the data and its relevance for their use case—or worse, misuse the data for a purpose it was not intended for.






















Let's personalize your content