

In-place version upgrades for applications on Amazon Managed Service for Apache Flink now supported
AWS Big Data
MAY 23, 2024
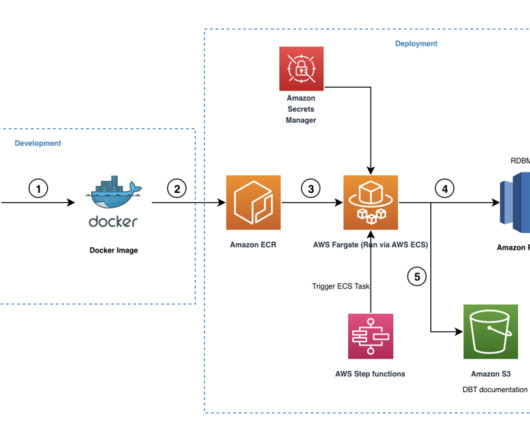
The next recommended step is to test your application locally with the newly upgraded Apache Flink runtime. After you have sufficiently tested your application with the new runtime version, you can begin the upgrade process. Refer to General best practices and recommendations for more details on how to test the upgrade process itself.








































Let's personalize your content