
A Guide To The Methods, Benefits & Problems of The Interpretation of Data
datapine
JANUARY 6, 2022
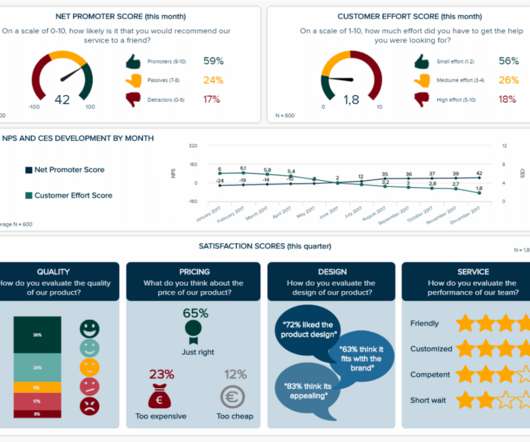
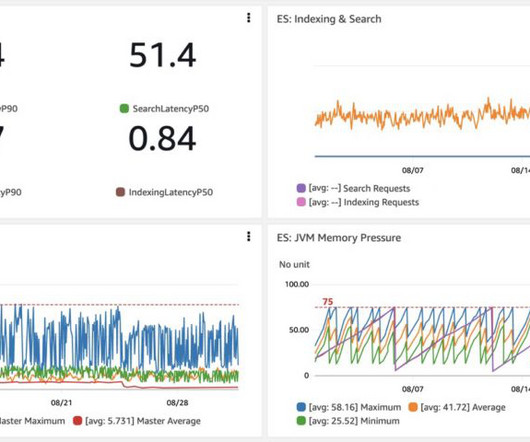
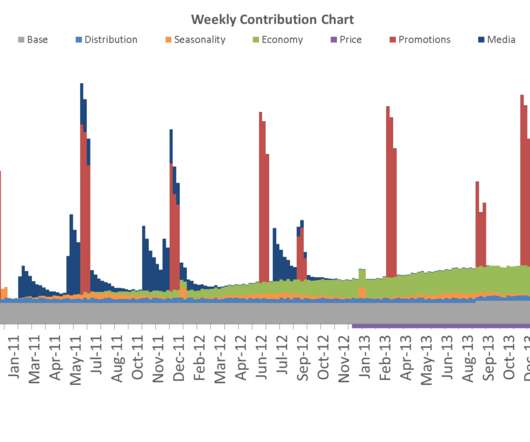
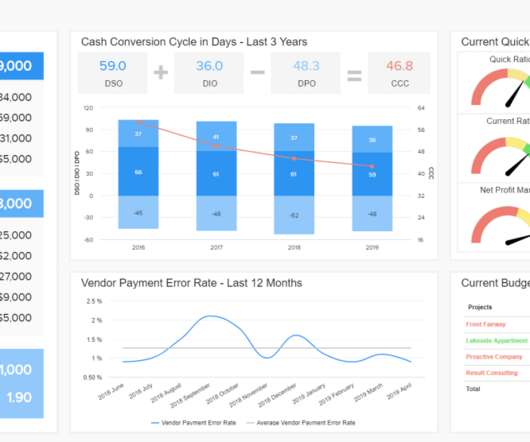
In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 Typically, quantitative data is measured by visually presenting correlation tests between two or more variables of significance. This helps businesses to develop responsive, practical business strategies. trillion gigabytes!




















Let's personalize your content