

Design a data mesh pattern for Amazon EMR-based data lakes using AWS Lake Formation with Hive metastore federation
AWS Big Data
JUNE 10, 2024
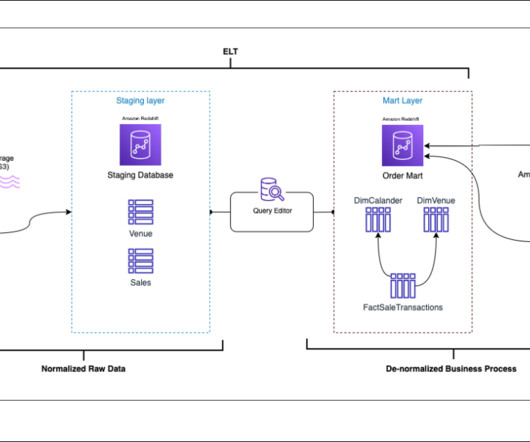
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based data lakes – Producers generate data within their AWS accounts using an Amazon EMR-based data lake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
















































Let's personalize your content