

Modern Data Architecture: Data Warehousing, Data Lakes, and Data Mesh Explained
Data Virtualization
OCTOBER 5, 2022
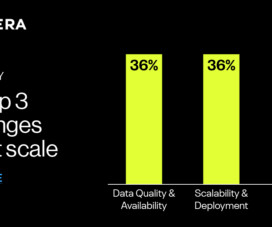
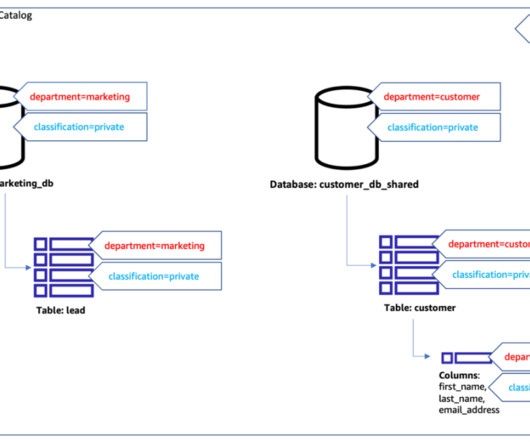
Reading Time: 3 minutes At the heart of every organization lies a data architecture, determining how data is accessed, organized, and used. For this reason, organizations must periodically revisit their data architectures, to ensure that they are aligned with current business goals.













































Let's personalize your content