


How Salesforce optimized their detection and response platform using AWS managed services
AWS Big Data
APRIL 18, 2024
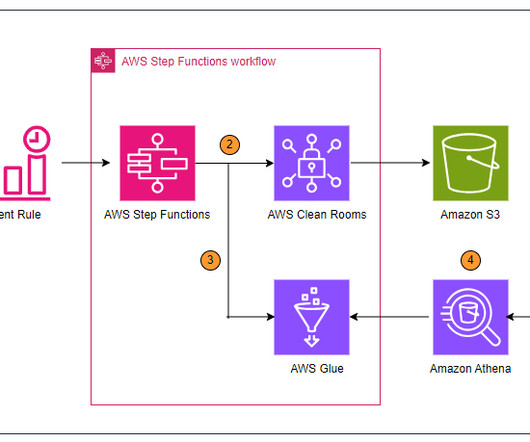
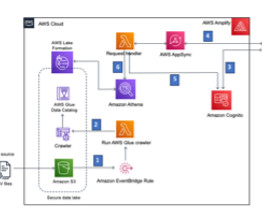
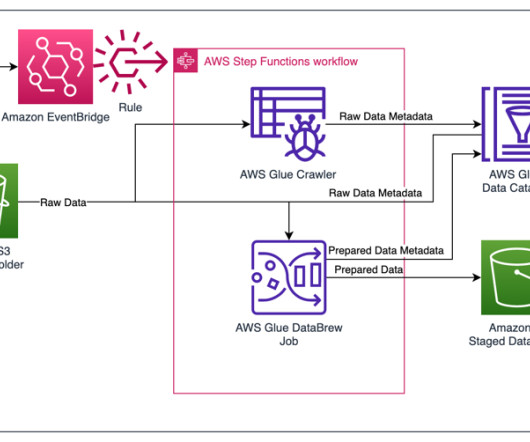
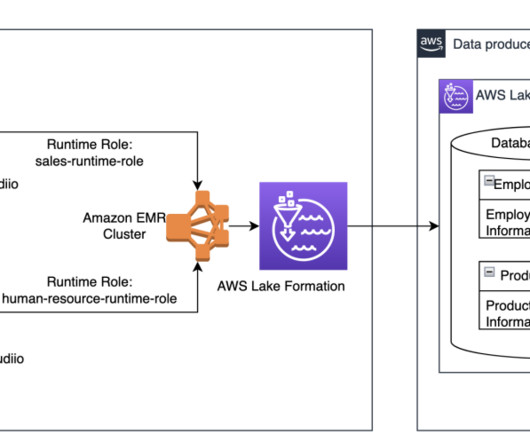
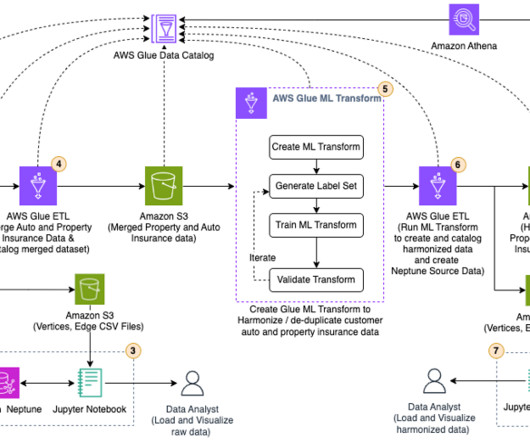
This is a guest blog post co-authored with Atul Khare and Bhupender Panwar from Salesforce. The platform ingests more than 1 PB of data per day, more than 10 million events per second, and more than 200 different log types. The data lake consumers then use Apache Presto running on Amazon EMR cluster to perform one-time queries.









































Let's personalize your content