

Simplify operational data processing in data lakes using AWS Glue and Apache Hudi
AWS Big Data
SEPTEMBER 13, 2023
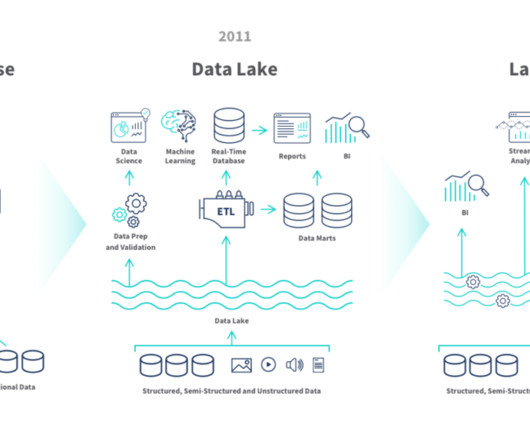
A modern data architecture is an evolutionary architecture pattern designed to integrate a data lake, data warehouse, and purpose-built stores with a unified governance model. Of those tables, some are larger (such as in terms of record volume) than others, and some are updated more frequently than others.

































Let's personalize your content