
Business Strategies for Deploying Disruptive Tech: Generative AI and ChatGPT
Rocket-Powered Data Science
FEBRUARY 15, 2023
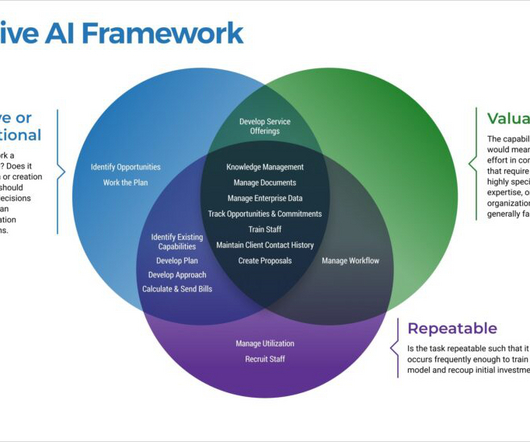
3) How do we get started, when, who will be involved, and what are the targeted benefits, results, outcomes, and consequences (including risks)? Keep it agile, with short design, develop, test, release, and feedback cycles: keep it lean, and build on incremental changes. Test early and often. Test and refine the chatbot.














































Let's personalize your content