

Business Intelligence vs Data Science vs Data Analytics
FineReport
JULY 28, 2021
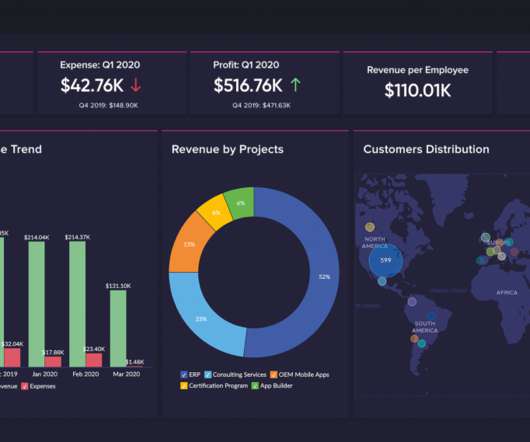
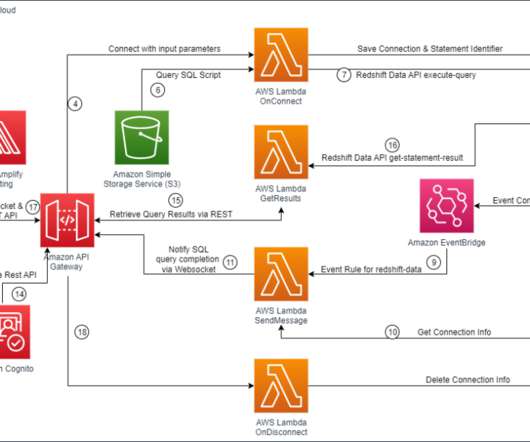
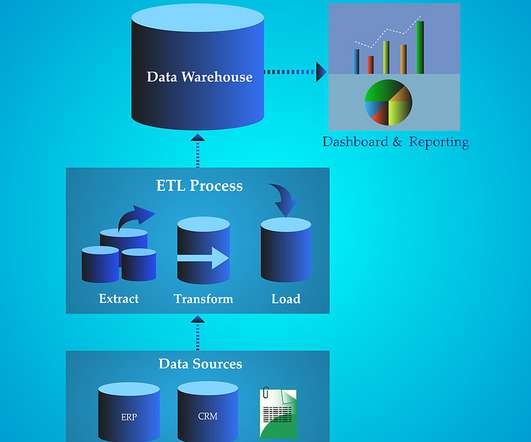
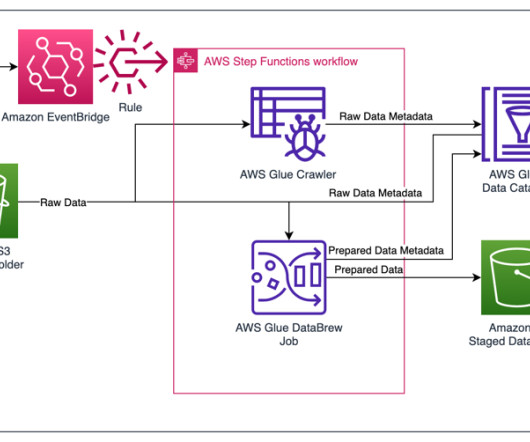
If you are curious about the difference and similarities between them, this article will unveil the mystery of business intelligence vs. data science vs. data analytics. Definition: BI vs Data Science vs Data Analytics. Typical tools for data science: SAS, Python, R. What is Data Analytics?












































Let's personalize your content