

How Cloudinary transformed their petabyte scale streaming data lake with Apache Iceberg and AWS Analytics
AWS Big Data
JUNE 10, 2024
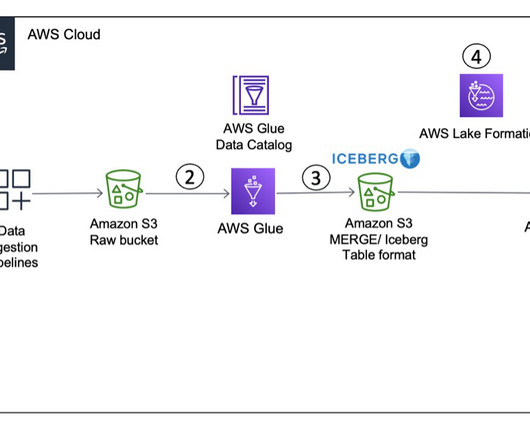
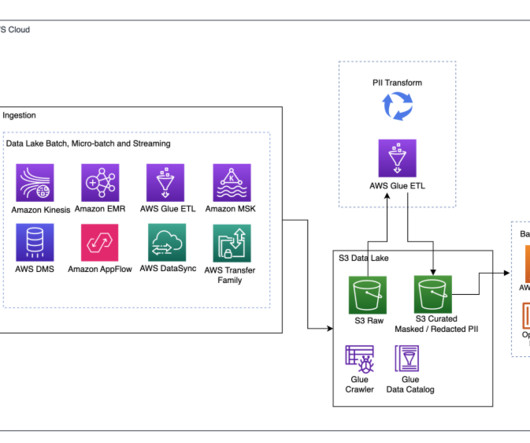
A modern data strategy redefines and enables sharing data across the enterprise and allows for both reading and writing of a singular instance of the data using an open table format. Determining optimal table partitioning Apache Iceberg makes partitioning easier for the user by implementing hidden partitioning.


























Let's personalize your content