
Detect, mask, and redact PII data using AWS Glue before loading into Amazon OpenSearch Service
AWS Big Data
JANUARY 12, 2024
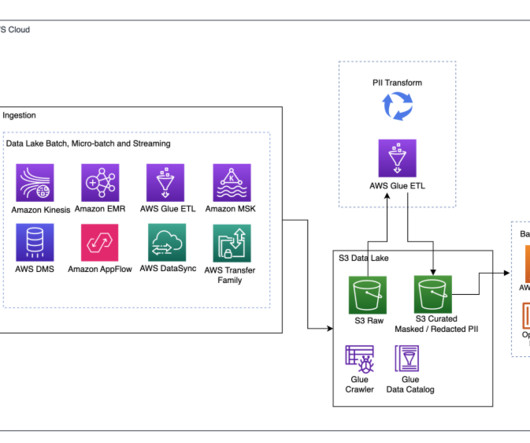
Ingestion: Data lake batch, micro-batch, and streaming Many organizations land their source data into their data lake in various ways, including batch, micro-batch, and streaming jobs. Amazon AppFlow can be used to transfer data from different SaaS applications to a data lake.























Let's personalize your content