

Bridging the Gap: How ‘Data in Place’ and ‘Data in Use’ Define Complete Data Observability
DataKitchen
SEPTEMBER 21, 2023
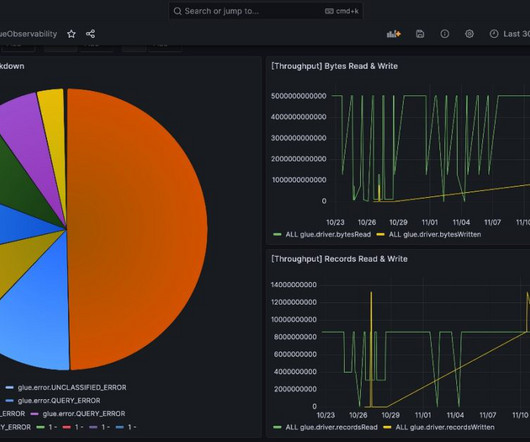
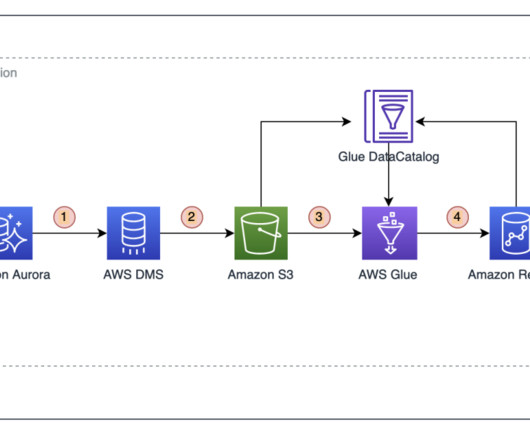
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize data warehouses or lakes to arrange their data into L1, L2, and L3 layers.




























Let's personalize your content