
Introducing AWS Glue crawler and create table support for Apache Iceberg format
AWS Big Data
AUGUST 16, 2023
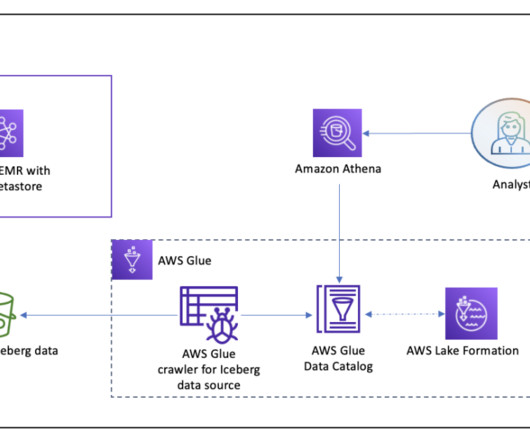
Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback. Solution overview For our example use case, a customer uses Amazon EMR for data processing and Iceberg format for the transactional data. Choose Create.



























Let's personalize your content