

How Cargotec uses metadata replication to enable cross-account data sharing
AWS Big Data
JUNE 7, 2023
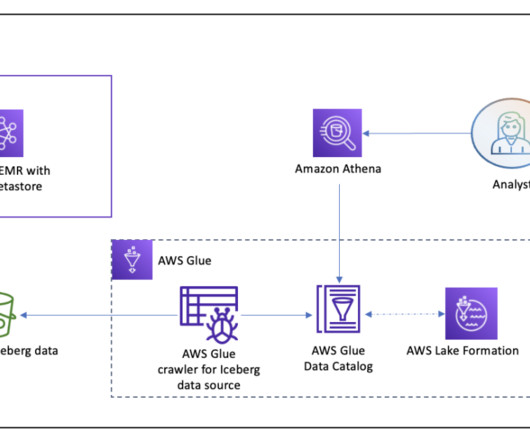
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a data lake, transformed, and made available for analytics, machine learning (ML), and visualization. The target accounts read data from the source account S3 buckets.



















Let's personalize your content