

Query your Iceberg tables in data lake using Amazon Redshift (Preview)
AWS Big Data
AUGUST 31, 2023
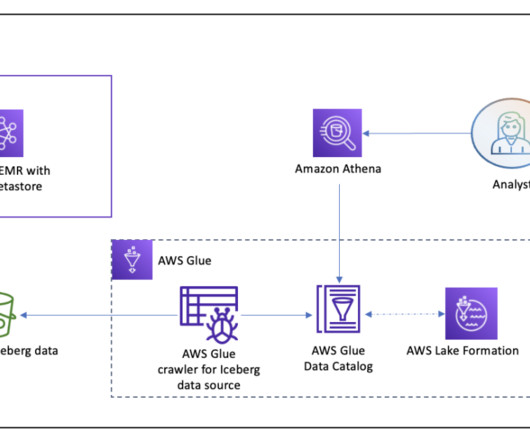
Amazon Redshift enables you to directly access data stored in Amazon Simple Storage Service (Amazon S3) using SQL queries and join data across your data warehouse and data lake. With Amazon Redshift, you can query the data in your S3 data lake using a central AWS Glue metastore from your Redshift data warehouse.















































Let's personalize your content