

Enable business users to analyze large datasets in your data lake with Amazon QuickSight
AWS Big Data
JUNE 23, 2023
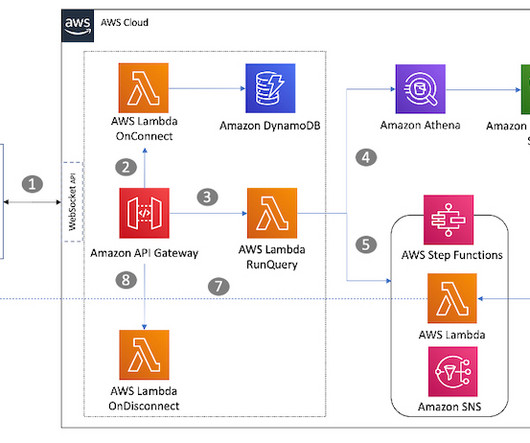
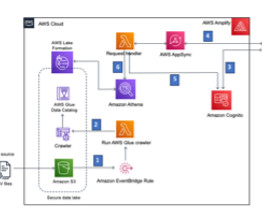
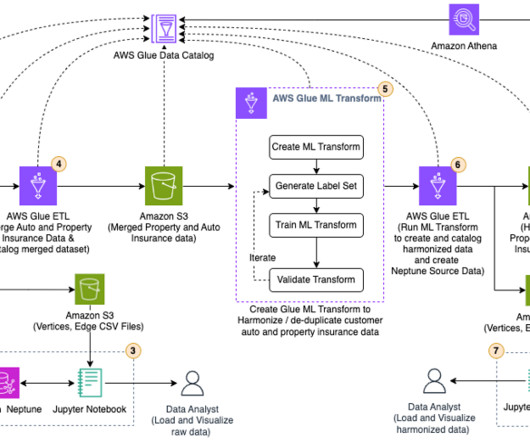
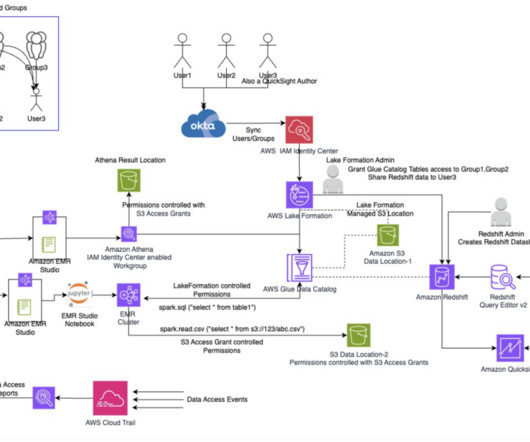
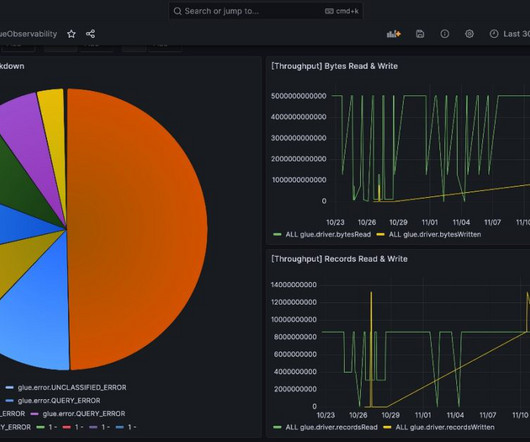
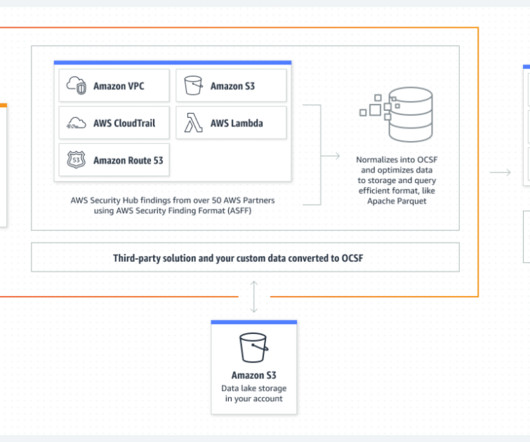
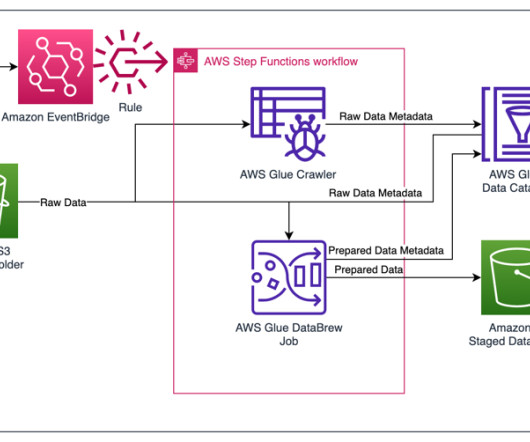
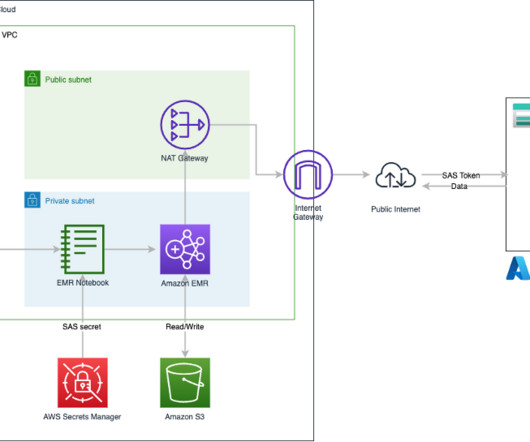
Events and many other security data types are stored in Imperva’s Threat Research Multi-Region data lake. Imperva harnesses data to improve their business outcomes. As part of their solution, they are using Amazon QuickSight to unlock insights from their data.

































Let's personalize your content